
Breaking Bad ... interfaces.
A question of efficiency.
So, you start working on some code and a monstrous interface snarls back at you, picking from its teeth pieces of the previous programmer who dared approach. It has twenty-five methods, and you just need to add one more teeny-weeny method to it. Should you clench and add it, or should you listen to that voice telling you that it's time to refactor? The Interface Segregation Principle says that you should hack that beast into an interface-salad but deadlines loom and managers would never understand. How can you quickly see which subset of interfaces you should choose?
Two approaches exist: the semantic and the syntactic.
Semantically, a programmer smashes a large interface into smaller ones by examining each method's purpose, identifying which methods, "Belong," together and creating interfaces based on these commonalities. Make no mistake: this is the best strategy. The only problem with this approach is that different programmers evaluate different commonalities differently. Ask six programmers to split a large interface and you might find six different decompositions.
The other is the syntactic approach. Whereas semantics concerns meaning, syntactics removes all meaning and examines only the brute fact of relationship between client and interface method. Semantic concepts live in the head of the programmer, subjective; syntactic concepts live in the source code, objective. Being objective, a syntactic approach should allow an objective evaluation of just how, "Bad," an interface is before surgery, and just how, "Good," the patients(?) are afterwards.
Just for fun, let's attempt such an evaluation.
The ISP says that, "No client should be forced to depend on methods it does not use. ISP splits interfaces which are very large into smaller and more specific ones so that clients will only have to know about the methods that are of interest to them." So consider figure 1, showing a client class, ClientA, and its three dependencies on interface I's five methods.
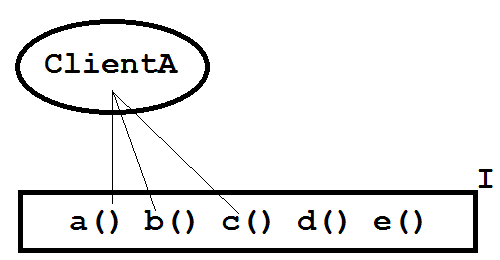
Figure 1: Client class ClientA and interface I.
Is interface I bad? Well, the interface exposes ClientA to three methods that it does use and to two methods that it does not. Perhaps the question is not whether the ISP is violated but to what degree. Might we therefore ask how efficiently the interface I is used by its clients?
Let's define that the efficiency of a client's use of an interface is the number of methods that the client calls on the interface divided by the total number of methods in that interface, expressed as a percentage. So as ClientA uses only 3/5ths of interface I we can say that interface I is 60% efficient with respect to that client. And what if two clients nibble on the interface? See figure 2.
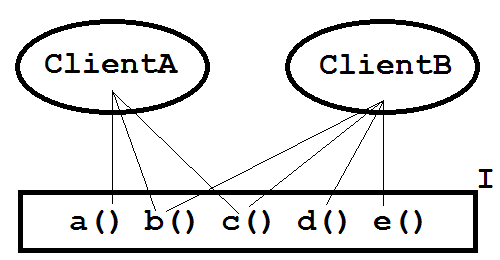
Figure 1: Two client classes and interface I.
Figure 2 adds a second class, ClientB, which depends on four of interface I's method, giving it a usage efficiency of 80%. The overall efficiency of I in this case is the sum of both efficiencies divided by the number of clients: (60% + 80%) / 2 = 70%.
Of course, we can define such arithmetic acrobatics any way we like, but this model of interface efficiency tries to capture the interesting aspects. As, "No client should be forced to depend on methods it does not use," then we would like our interface efficiency to fall as interfaces grow and clients depend on relatively fewer methods (which it does), and we would like it to rise as interfaces shrink and clients depend on relatively more methods (which it does).
And with an objective criterion, we can have machines do the work for us, bundling the calculations into an algorithm and stuffing it into a code analyzer so that it might sniff out the least efficient interfaces in our systems. How might we use such an algorithm?
We could make a few educated guesses, splitting a large interface into smaller ones, having our algorithm calculate the before and after efficiencies, and proposing those splits with the highest efficiencies.
But we can be even lazier.
An interface has a low efficiency because one or more of its clients depends on too few of its methods; so what if we have our algorithm scan all clients of our interface, hypothetically extract from the interface the methods each client calls, and then predict the efficiency of the remaining interface? This might help identify which subsets of methods in the interface, "Belong," together as the extracted interfaces reflect not a programmer's notion of commonality but actual client use. We could then extract those methods that give the original interface the best efficiency gain and start the process again.
But we can be even lazier.
What if we tell our algorithm, "Listen, don't just give me a list of potential interface extractions, but simulate the extraction of the most efficient and then repeat the process on that remaining interface, cumulatively predicting a path that makes the original interface increasingly efficient. And keep going until there's nothing left to extract. And be quick about it, the day's gettin' old." This would then provide us not just with a suggestion of an interface to extract but a full roadmap of extractions that lead to a distant but high efficiency.
Of course, we would not then blindly follow this roadmap: semantic decomposition trumps all. These syntactic suggestions might, however, help us evaluate our choice. If we find that they support our fine commonality guesses, so much the better.
Puddings'n'proof.
Let's try it out. Let's take some honest hard-working Java code and pour it into the algorithm to see what oozes out. (Spoiklin Soice has been updated with the algorithm: right click on a class and select, "Suggest extraction".)
As usual, the most recent structural investigation - presently, FitNesse - will provide grist for the analytic mills. FitNesse's average interface efficiency is impressively high. Interfaces tend to be small and finding large inefficient interfaces proves difficult, but we do find a candidate in interface WikiPage.
WikiPage has 19 methods (so is not too obese) and is only 15% efficient, partly because of the huge number of clients, 104, few of which call all of its methods. The list below presents these methods, along with their percentage use (yes, you can calculate that, too, from the model):
getPageCrawler: 68.3%
getData: 61.5%
getName: 32.7%
commit: 23.1%
getParent: 15.4%
getChildren: 12.5%
getChildPage: 9.6%
addChildPage: 8.7%
getExtension: 7.7%
hasExtension: 6.7%
getDataVersion: 5.8%
getHelpText: 5.8%
removeChildPage: 5.8%
hasChildPage: 5.8%
getActions: 4.8%
getParentForVariables: 4.8%
setParentForVariables: 3.8%
getHeaderPage: 3.8%
getFooterPage: 3.8%
Take a moment: based on whatever meaning you care to take from these names, how would you split this interface? If we have our algorithm plot a road-map of extractions, it suggests that the extraction which will raise this interface's efficiency highest (to 24%) is the following:
addChildPage
getPageCrawler
commit
getData
getParent
hasChildPage
getName
getChildren
removeChildPage
A perfect semantic decomposition would have produced an extracted interface all of whose methods would share some obvious commonality and the above is no such decomposition. That commit() seems a little odd, for instance. Nevertheless our semantic brethren may not be too displeased with this overall suggestion: it seems heavy on "child" and "parent", and semanticians like that sort of thing. If we had guessed to break out a smaller interface to focus on relationships, then the above might offer some validation. Moving on, the algorithm next suggests the following interface extraction, bringing the remaining methods' efficiency to a whopping 63%:
getActions
setParentForVariables
getHelpText
getHeaderPage
getChildPage
getParentForVariables
getFooterPage
Again, the beefy rugged setParentForVariables() method looks like it's wandered into the perfume department of the store, but the suggestion seems quite "page"-heavy. Whereas the first interface also dealt with pages - the donor is WikiPage after all - this interface seems less concerned with relationships and more on page mechanics: headers, footers, help-text and actions, for example. So once more it may offer some consolation had we initially thought to extract an interface based on web-page details.
The final suggested extraction to bring us to 100% efficiency is the delightful:
getExtension
hasExtension
A more coherent interface we could not wish for. Indeed, that a purely syntactic algorithm can unearth so semantically coherent an interface hints at careful thought having been put into FitNesse's interface's design.
You get the point, though a further example is available here, and some of Spoiklin's own dirty laundry is here (oh, the shame!).
Summary.
Machines cannot design good, small, efficient interfaces for us - algorithms do not understand the methods they scrutinize - but they can offer a client-use statistical perspective. If algorithms happen to suggest an interface extraction that meets approval, this only reflects that the designers of the original interface had a good idea of how clients would use various parts of it, if not the whole.
Programmers are sailors. They sail not calm tropical seas but frozen arctic oceans, their ships surrounded by an ever-shifting ice-pack, in which the primary competing forces - those of functionality-delivery and structural maintenance - threaten daily to crush their hulls. They discard no navigational tools, no matter how inconsequential.
</purple>
Notes.
Slightly more formally: given a set of n interfaces where the ith interface is Ii and a set of m client classes, and given that the number of methods in the ith interface is |Ii| and the number of client classes of ith interface is |Ci| and the number of methods that the jth client depends on in the ith interface is given by |Uji|, then the efficiency of the n interfaces is given by:
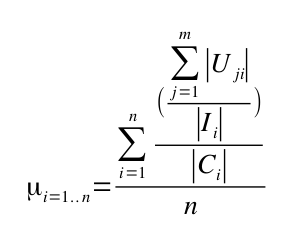
Also, the algorithm needs a few more constraints than just this equation: for example, we don't want it to pull out too many single-method interfaces, which are 100% efficient but a little ... overkill. Nevertheless, the above equation remains key.