
Structure and information.

The basics.
How much information is in a coin-flip?
Or in the word, "Soup?"
Or in the throw of two dice?
Over such questions have great minds brooded, among them the brilliant Swede Harry Nyquist, followed by Americans Ralph Hartley and - giant among giants - Claude Shannon. Their answers revolutionized human thought and birthed information theory itself.
Information theory, of course, charts an enormous intellectual landscape to which a blog post can do little justice. Some introduction, nevertheless, is required (with thanks to ArtOfTheProblem's magnificent ten-minute video How do we measure Information?).
Basically, we can estimate information of in unknown quantity by asking a series of questions which admit only yes/no answers. If someone secretly flips a coin and we wish to discover whether the coin landed on heads or tails, we can ask the question, "Is it heads?" Whatever the answer, we can ascertain the outcome, as even a, "No," answer implies that the coin must have landed on tails. It turns out that, given a number of possible symbols, X, we can find the number of bits of information in the selection of one symbol by taking the base-two log of X. Having two outcomes a coin-flip contains (because log2(2)=1) one bit of information.
The word, "Soup," comprises four letters, each fished from a twenty-six character alphabet. A wise first question to ask when guessing any particular letter - a question which maximizes search efficiency by discarding half the possible solutions - would be, "Is this letter before letter N in the alphabet?" Each subsequent question should again half the space of possible answers so that, on average, guessing any letter would require log2(26) questions. With four letters, the word, "Soup," thus contains 4 x log2(26) = 18.8 bits of information.
A desperate gambler throwing a normal six-sided die makes a selection from six symbols, the throw thus containing log2(6) bits of information, the throwing of two dice therefore containing 2 x log2(6) = 5.2 bits.
Information theory has long offered such insights but can we shine its perspicacious beam onto Java source code? Can we calculate the amount of information in a Java program's structure?
Structural information.
Consider the following rudimentary Java code, in which method a() has dependencies on methods b(), c() and d().
class Test {
void a() {
b();
c();
d();
}
void b() {
System.out.println("Hi from b()");
}
void c() {
System.out.println("Hi from c()");
}
void d() {
System.out.println("Hi from d()");
}
}
Figure 1 portrays this code as a spoiklin diagram showing the method dependencies descending the page.
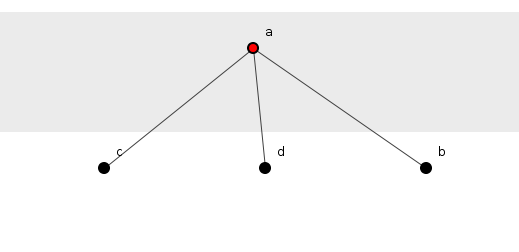
Figure 1: A method calling three others.
Do these methods have structural information? What, for instance, is the structural information content of the method a()?
We might say that a method's structural information is that afforded to it by its being embedded within a structure, at a position established by its relation to other methods. Structural information then reflects the means by which a method relates to others, specifically the dependency alternatives available to a given method in navigating to those on which it depends.
Method a()'s position in its structure is entirely defined by its being the top-most element from which radiate dependencies on the other three methods of the system. Navigating from a() to the next method in the structure involves selecting one of three alternatives, the information required to make this selection - using the logic introduced above - being log2(3) = 1.58 bits. As three such alternatives lie open to a() then it contains 3 x 1.58 = 4.75 bits of information.
None of the other methods - b(), c() or d() - permits navigation to any other and hence each contains no information. If the information of the structure is the sum of the information of all elements, then the entire structure contains 4.75 bits of information.
In general, therefore, we can calculate the information in an element by multiplying the number of dependencies from that element to all others by the base-two log of that number of dependencies. The total information then of n elements, where the ith element has xi dependencies on other elements is given by:
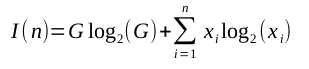
(That odd G log2(G)-term in what might otherwise be a vaguely entropy-looking equation will be explained in a moment.)
Figure 2 shows a slightly expanded version of this system in which the methods of figure 1 embroil themselves in a nobler struggle.
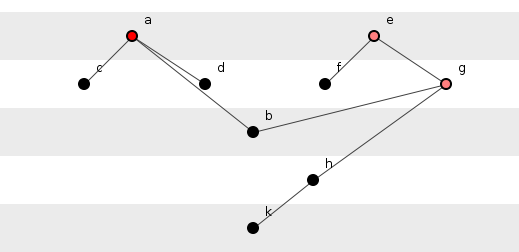
Figure 2: Two sub-groups of methods.
Calculating the information of figure 2 proceeds directly from the analysis of figure 1 with each method having an information quantified by the number of its dependencies multiplied by the base-two log of that number, and with methods with no dependencies having no information. Indeed the figures here colour-code information content with black representing informationless methods and increasing depth of red representing methods of increasing information content.
Two points stand out as noteworthy.
First, method h() has no information despite its depending on k(). Informationlessness does not restrict itself to the childless. A whole slew of methods can contain precisely zero information if stretched out a line and pulled taut as a guitar string.
Secondly, the information of this grander system cannot be that contained only in its methods because, unlike in figure 1, there are two top-most methods, that is, two methods on which there are no dependencies. Thus the information of a() depends on its being chosen instead of e(): a selection must be made to decide between these two methods. This selection generates an information equal to the number of top-most methods multiplied by the base-two log. Hence the G log2(G)-term of the above equation - G being the number of top-most methods - a term which usually dominates a system's overall information content.
This new system then contains 10.8 bits of information, less than that of the word, "Soup."
Information as design cue.
Can structural information inform the design of better programs?
This question raises the concept of efficiency. Engineers of the industrial revolution often bolted together better steam engines simply by increasing the efficiency with which these engines converted the heat of burning coal into mechanical work. Such a measure might also serve here, allowing programmers to judge a program's worth by the efficiency with which the program converted (in some sense) its information into structure.
There is, however, a problem.
To entertain an efficiency, a system must accommodate three values: a theoretical minimum, a theoretical maximum and an actual, thus providing a scale along which a system may calibrate itself. Although structural information indeed provides three such points, the scale suffers from withering impracticality, with even small programs spewing potentially gargantuan quantities of information and rendering the efficiency of all programs uninformatively low. (See here for details).
Fortunately, other approaches exist. One such proposes the building of a hilariously simplified model of source code structure.
Consider figure 1 again. This displays what we shall call a, "Sub-group," of four methods with method a() at its head. The sub-group separates into two layers, defined by parent-child relationships and depicted by the horizontal banding. The sub-group thus stands two layers deep: method a(), the parent, sitting alone in one layer, methods b(), c() and d(), the children, in the other. Four values therefore parameterize this structure and constitute the model to be investigated: the number of methods, n; the number of sub-groups, G; the depth of layering, D; and the number of child-methods of each parent, C. In the case of figure 1: n = 4, G = 1, D = 2 and C = 3, see figure 3.
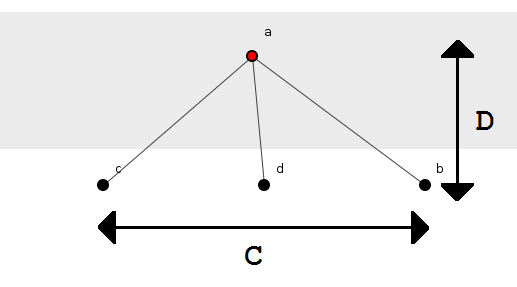
Figure 3: A small parameterized system.
Figure 4 shows another example, this time of forty-two methods (n = 42), of two sub-groups (G = 2), three layers deep (D = 3) and with each parent having four child methods (C = 4).
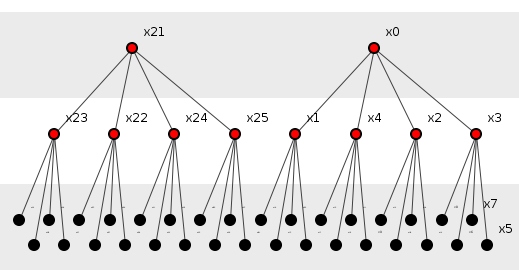
Figure 4: A large parameterized system.
This model is an example. It is a toy. Its ludicrous regularity and absence of multi-parented child methods clearly brand it unrealistic. Despite its flaws, however, the model encapsulates some features of real programs: real programs also harden into groups of methods in which parent methods sprout multiple child methods, and these groups often extend generations deep. The model allows us, furthermore, to spin the knobs of its four parameters and gaze as twitching needles plot the information content of its various configurations. Documenting thousands of real systems to glean such data might take an age. The model delivers this flexibility because its four parameters click into two equations (with closed forms) that yield its information as follows.
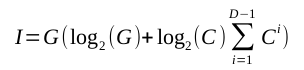
Where:
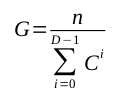
Though unappetizing, these equations tell us that figure 4, for example, describes a system of 82 information bits.
Configurations, they are a-changin'.
Let us experiment on such a toy system of, say, 3000 methods. This fixes our first parameter, n = 3000, and leaves three unconstrained. Three parameters being still too rowdy, we shall also fix a second parameter and perform three separate experiments in which the final two shall vary reciprocally.
Firstly, let us make the system shallow. Sensibly shallow. Let us make it just three layers deep. With this fixed depth, let us plot the information as the number of children varies, see figure 5.
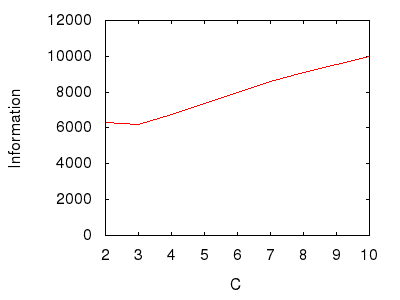
Figure 5: Varying the number of child methods.
Figure 5 shows, for example, that a system of 3000 methods in which the, "Top," parents have three children and nine grandchildren (but no great-grandchildren) enjoys an information content of approximately 6,000 bits. A system of 3000 methods in which top parents have four children and sixteen grand-children brandishes around 6,500 bits of information, and so on. The absolute figures hardly matter: what matters is that the system's information content (after an initial dip) rises as the number of child methods per parent increases.
Simplistically: the more children, the more information.
Information essentially measures the number of selections available when departing from a particular method. As having more child methods would seem to broaden any such navigation options, it might not surprise that our model unearths this first correlation.
As a second experiment, again with 3000 methods, let us now fix the number of child methods at three per parent and instead vary the depth of the system, that is, we start with a system of only parents and children (two layers), then a system of parents, children and grandchildren (three layers), etc. See figure 6.
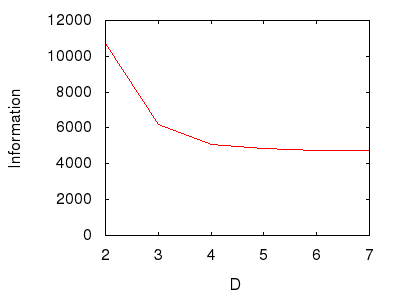
Figure 6: Varying the system depth.
Figure 6 shows shows the opposite effect of the first experiment, namely that as the depth of the system increases it loses information. This might seem odd as surely the, "Deeper," a system the more tangles might hinder any navigation. But no, because to increase a system's depth requires making it, "Narrower," at the top, thereby providing fewer and fewer starting points from which the deepest methods may be reached. These fewer starting selections outweigh - apparently - the increasing selections further down.
Again, simplistically: the deeper, the less information.
Figure 7 takes a different tack. It investigates sub-group effects. Although fixing again the number of child methods per parent at three, it instead varies the number of sub-groups that constitute the system.
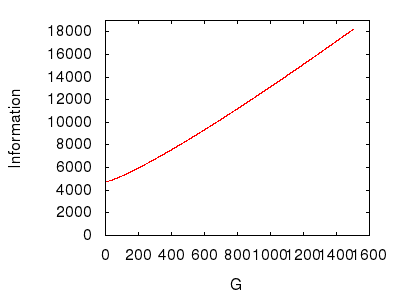
Figure 7: Varying the number of sub-groups in the system.
Figure 7 shows that a system gains information as its number of sub-groups increases. This suggests a corollary to the logic deployed in the previous experiment. In figure 7, starting with few sub-groups and adding more implies that the system is growing, "Wider," and hence offering more initial selections from which to begin navigating dependencies. Given the fixed number of methods, this widening must necessarily reduce the system's width, which, in contrast to the previous experiment, causes the system to gain information.
A final evaluation: the wider, the more information.
The principle of depth.
Does any pattern or unifying principle emerge from these scattered findings?
Well, maybe.
The principle of depth holds that source code structure degrades as it deepens, with ripple effects causing greater devastation in deep structures than in shallow. The above experiments suggest that deep structures contain less information than shallow. Information, therefore, seems to correlate with shallowness and hence the more information a system boasts, the better its structure.
This, however, runs afoul when pushed to extremes as fully-connected systems (in which methods depend on huge numbers of other methods) exhibit most information yet programmers would hardly promote the idea that systems should be fully connected.
Perhaps, "Too early to tell," is the only conclusion we can reach at this point.
Summary.
Structural information attempts to measure the degree of selectability involved in navigating from one method to another (or from one class to another, or from one package to another).
In certain otherwise well-structured systems, there may exist a correlation between increasing information content and improving design.
But at present this correlation remains ... tenuous.