
Is there any evidence for ripple effect?
This blog has droned on and on about ripple-effect husbandry (or lack thereof) and its determining the quality of source code structure. Ripple effect - whereby gently polishing code in one place radiates wobbles and cracks and shattering crashes far and wide - was defined in 1974 and has guided structural toil ever since.
But does it really exist?
Or rather: where is the evidence that ripple effect exists? How would you gather such evidence?
Imagine you had 100 glass marbles: 40 red and 60 blue. No, not blue: yellow. You throw them on the floor, close your eyes and pick up one at random. What's the probability that the marble you selected is red?
If you answer, "0.4," or "40%," then well done: you grasp probability theory. Replace the marble and repeat the experiement 10,000 times: you will find that your selection history closely approximates that initial ratio: perhaps 4095 red to 5905 yellow. Love that law of large numbers.
Changing the experiment trivially for reasons that will shortly become clear: let's say you now have 10,000 scattered marbles - 4,000 red, 6,000 yellow - and instead of selecting a single marble, you pick up, say, 200 marbles at random and put them in a bag. What proportion of this sample will be red marbles?
Yes: approximately 40%. This is really little different from performing the single selection 200 times: if there's a 40% chance of selecting a red marble, then roughly (though seldom exactly) 40% of the marbles in your bag will be red.
Now, consider a method invoking another method, that is, depending on another method. Let's call all methods that do not depend on any others, "Child methods," and all methods that do depend on any other, "Parent methods." Hence in figure 1, only a() is a child method.
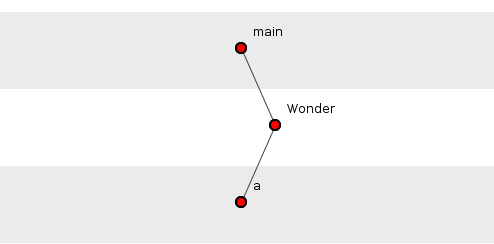
Figure 1: main() and Wonder() are parent methods, a() is a child.
Imagine you have a system of 10,000 methods, 40% of which are parent methods and 60% of which are child methods. Chose 200 methods at random. What will be the ratios of parent and child methods in your selection?
Yes: approximately 40% of the methods will be parent methods. This is the same experiment as with the bag of marbles above.
Total snoozefest so far, right?
Now, however, let's examine some real Java software systems as they were released over time and let's select a number of methods in each successive release. We won't, however, select randomly. Instead, we'll select those methods updated during that release.
Programmers update methods for many reasons, but few meetings begin with, "Quick! We need to update 300 parent methods - which ones will we chose?" So if we select the updated methods of a release, of course that selection itself is not random in that programmers do not sit around in their underwear flipping coins to chose which methods to update. Yet nor do they explicitly select for parentness or childness, so whether a parent or child is selected should be random because mentally balanced programmers don't care. If a release contains 40% parent methods and 60% child methods, then we should expect to see these proportions reflected approximately in the set of methods updated in that release: 40% of the updated methods should be parents, 60% of the updated methods should be child methods. Roughly.
Ripple effect, however, predicts something different.
Ripple effect concerns dependencies, those, " ... paths along which changes and errors can propagate into other parts of the system." With the direct dependency from parent to child being the strongest dependency, ripple effect - if it exists - predicts that there will be a slight bias towards parents in the set of updated methods: more parents will be updated than child methods. This is because whereas both parent and child methods can be updated independently, there is a greater probability that a parent method will be updated because of a child's update rippling to it, than vice versa (as parents depend on child methods, not vice versa).
Certainly, if there were no bias towards parents in the updated set, then we may even have evidence that ripple effect does in fact not exist and forty years of software structuring could be chucked in the river in a black plastic bag.
Figure 2 shows 21 successive releases of the Apache Maven core jar file. The red line shows the percentage of Maven's methods that were parent methods in any given release, which is also the percentage of that release's updated methods that are predicted to be parent methods. The blue line shows the percentage of updated methods that were actually parent methods in each release.
If ripple effect exists, the blue line should be higher than the red.
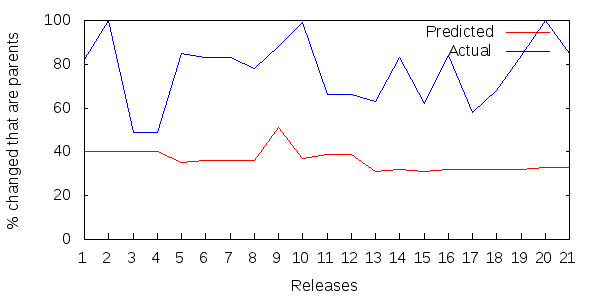
Figure 2: Parent updates as a percentage of all updated methods per Maven release.
Wow.
That's not just a little bias. Parent methods form a vastly larger proportion of Maven's updated methods than we would expect if both parents and child methods shared the same probability of update.
But perhaps Maven is somehow an oddity? We need to inspect hundreds of thousands of method revisions in completely independent software projects to draw any conclusions. Fortunately ...
Figure 3 shows 19 successive releases of FitNesse.
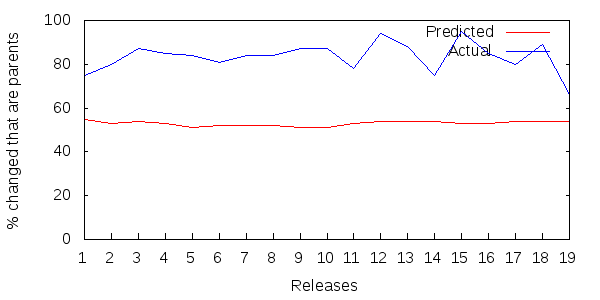
Figure 3: Parent updates as a percentage of all updated methods per FitNesse release.
Figure 4 shows 13 successive releases of JUnit.
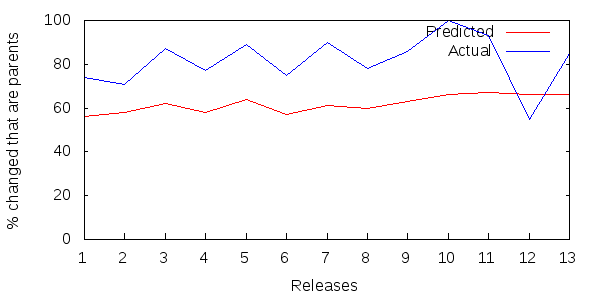
Figure 4: Parent updates as a percentage of all updated methods per JUnit release.
Figure 5 shows 21 successive releases of the Apache log4j core jar file.
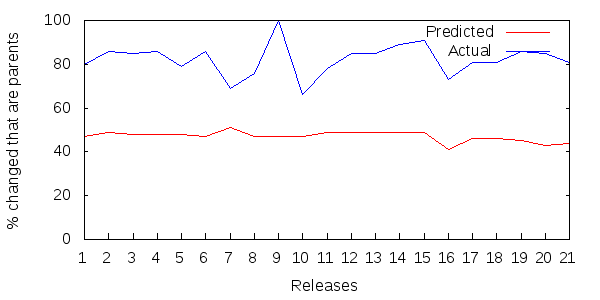
Figure 5: Parent updates as a percentage of all updated methods per Log4J release.
Figure 6 shows 25 successive releases of the Apache Lucene core jar file.
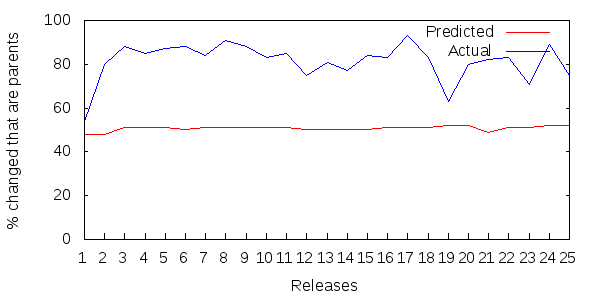
Figure 6: Parent updates as a percentage of all updated methods per Lucene release.
Figure 7 shows 21 successive releases of the Spring core jar file.
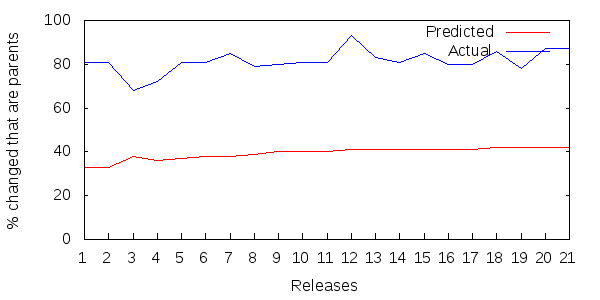
Figure 7: Parent updates as a percentage of all updated methods per Spring release.
Figure 8 shows 19 successive releases of Struts.
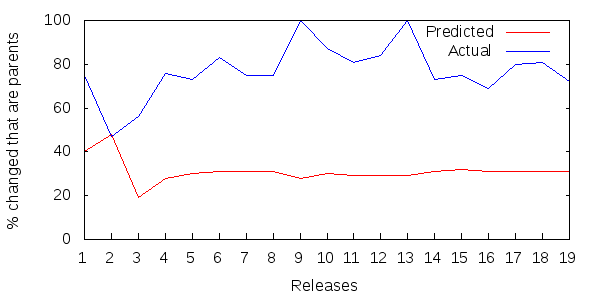
Figure 8: Parent updates as a percentage of all updated methods per Struts release.
Summary.
No one seriously doubts the existence of ripple effects, and all of this is, really, blindingly obvious. The above, futhermore, presents not evidence but correlation (and, what's more, correlation facing a host of validity-threats). As a foundation for all syntactic software structuring everywhere ever, however, even an unrefined correlation sometimes convinces where just saying, "It's blindingly obvious," does not.
To a previous post which attempted to show the structural utility of comparing dependency distributions, the excellent Paul Hanchett made an insightful comment, pointing out that coupling - methods calling methods - " ... can introduce adverse dependencies between sections of code. It's that dependency that you're trying to avoid, not the coupling."
This post tried to find just that correlation between merely depending on a method and an increased probability of being updated because of that dependency. Hence we'll name this, "The Hanchett Correlation," unless Paul objects.