
What's the opposite of duplication?

"If you see the same code structure in more than one place," writes Martin Fowler in his wonderful, Refactoring book, "You can be sure that your program will be better if you can find a way to unify them." He then describes how skillful programmers use the twin scalpels of extraction and substitution to excise duplicated expression and metastasized algorithm.
Almost lost in this flurry of fine advice lies the word, "Structure." Fowler seems to use it in a slightly unorthodox fashion. Structure being a set of elements and their relationships, that to which Fowler refers certainly expresses structure: the source code lines constituting the elements, sequential control flow, the relationships. And true, multiplicity in this context - lines of code - represents the most fundamental form of duplication, the one on which all other duplication builds. Yet other structure exists, structure of more traditional from, structure that also reflects - perhaps imperfectly - the underpinning textual substrate.
This higher level of structure models methods as elements and dependencies as relationships. What does duplication look like in this context? Figure 1 shows the spoiklin diagram of a program bedridden with the vile disease.
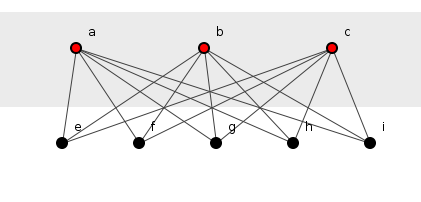
Figure 1: A first glimpse of structural duplication.
In figure 1, a() calls five other
methods, e(), f(), g(), h()
and i(). And so does b(). And so
does c(). This structural form does not preserve the
order of method invocation and hence figure 1 can only suggest and not
pronounce duplication - abstractions shed their information ballast as
they float up over the source code proper - but, as we shall see
later, pragmatism easily vanquishes such theoretical constraint.
Consider that figure 1 successfully identifies a structural
duplication, that a(), b()
and c() all house precisely the same sequence of method
invocations. What's to be done and what how should the structural
solution appear? The solution, of course, crushes the three sequences
together in a new method, d(), which the original top
three then call, see figure 2.
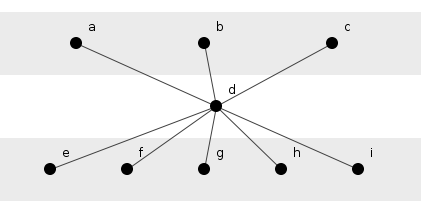
Figure 2: A structural solution.
Here we see, if not the opposite of duplication, at least the cost of its eradication: depth. The transitive dependencies of figure 1 are two elements long; in figure 2, they all stretch three elements long. This eradication comes, then, at the risk of increasing ripple effects but duplication, the root of all evil in software design, seems worth the price.
This may strike as rather trivial. What could be more obvious than such duplication reduction? On this point, most of the software greats stand in rare agreement. Fowler elevates code duplication to the first and most important code smell in his book. Kent Beck writes in his Extreme Programming Explained, "When the system requires that you duplicate code, it is asking for refactoring." J. B. Rainsberger professes just two requirements of simple design, one being that it, "Minimizes duplication."
The problem is that duplication minimization first requires duplication identification, a task at which, rather like performance optimization, machines excel and humans, sadly, do not. Several modern design processes urge programmers to satisfy functional requirements first and to postpone briefly those structural redresses necessitated by function-blinkered design. During this postponed refactoring, these programmers naturally focus on the newly accreted logic and so may fail to notice when local additions mirror existing code in distant unstudied packages.
The futility of such effort to manually root out duplication often
scars even the most popular programs long after their release. A
casual processing of the recently reviewed FitNesse
reveals it to be littered with many snippets of identical or nearly
identical code, most trivially small, but some boasting impressive
reach such as the tentacled PageDriver.requestPageSaveWithContentsByUserAndPassword()
and ResponseRequester.execute()
shown in figure 3.
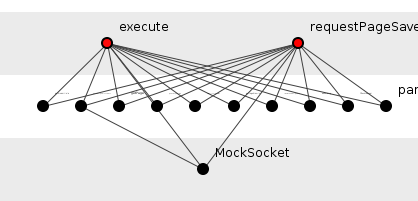
Figure 3: Structural duplication in FitNesse.
Zooming to a yet higher level, figure 4 presents the package diagram of the entire FitNesse program in which black celebrates those packages free from code duplication and packages hosting duplicated code are coloured red proportional to the number of duplications contained.
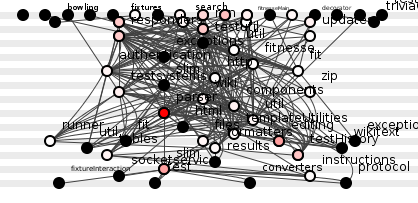
Figure 4: FitNesse package structure.
Figure 4 offers a summary of method-level structural duplication only; who knows what a line-by-line code analyzer might reveal? Indeed, so widespread a problem has this become that some programmers have abandoned all attempts to manually identify code duplication, instead relying exclusively on their unfailing source code analyzers to expose problems.
Is it not odd that duplication still commands such dread respect when brainless mechanization spells its thorough demise?
Summary.
The excellent Robert C. Martin, author of the above FitNesse, perhaps said it most eloquently: "Duplicated code is the root of all evil in software design. When a system is littered with many snippets of identical, or nearly identical code, it is indicative of sloppiness, carelessness, and sheer unprofessionalism. It is the guilt-edged responsibility of all software developers to root out and eliminate duplication whenever they find it."
Send in the drones.