
Metrics considered charmful
Testing can be abused so we should stop writing JUnit tests.
The legal system can be abused so we should close the courts.
Government power can be abused to we should ditch democracy.
Summary.
Now just wait a gosh-darned ...!
These are, of course, ludicrous arguments: that a process can be abused provides no justification for its eradication.
Yet something of this mindset hovers over the programming community's view of source code metrics. Most programmers view code metrics reasonably, seeing them as an extra pot of information about - though hardly the definitive appraisal of - the state of their code. Some, however, when faced with metrics, cite Goodhart's law, hint that the mere choosing of a metric to measure will automatically invalidate it, and proceed to build code without formulating metrics at all.
This is a shame.
The great benefit of metrics is that they shunt subjectivity off minds and onto fingertips, transporting discussion from the realm of ideas to the crisp black-and-white of source code. You may or may not agree on the representative value of a particular source code property, but while that property remains a thought exercise, all parties are free to imagine and argue for (or against) their own varying interpretation.
Once you convert that property into a metric - and, better still, into a algorithm running in a source code analyzer - you've made the property objective, common to all views and truly negotiable.
Take, for example, package coupling.
Oh, we all loooooooooooooooove moaning about Sara's hideously coupled packages and Micheal's ridiculously high-carb spaghetti-fests, but what do we really mean? How do we measure package coupling?
(Disclosure: this blog is no great fan of the terms, "Coupling," and, "Cohesion," due to their inherent contradictions, and what is described here should rather be called, "Sub-level dependencies," but the term, "Package coupling," used in isolation, seems harmless for now.)
Let's take a well-known Java open source project at random: Apache Maven. Figure 1 shows a spoiklin diagram of the packages in Maven's core jar file, with each circle representing a package, each line a dependency between two packages.
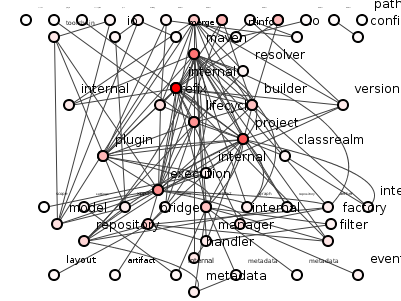
Figure 1: Maven core package structure.
A beauty queen this is not, but is package structure the same as package coupling?
If you ask the average programmer in the corridor, she might say that package coupling represents the "strength" (in some sense) of dependencies between packages, and that this this "strength" increases as more classes/interfaces are involved. So if package a depends on only one class in package b, then a is weakly coupled to b, but if a depends on ten classes in b then a is strongly coupled to b. So let's redraw figure 1 but with thickness of line relative to the number of classes depended upon, see figure 2.
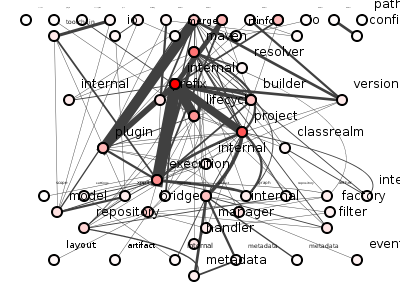
Figure 2: Maven core package coupling.
Good, we're getting somewhere. Immediately we can see that coupling reveals what structure alone does not, namely that a few central packages are heavily dependent on one another. And we can put a figure on our coupling: Maven core has 393 class dependencies that span package boundaries, so its package coupling, according to our provisional definition, is 393.
And the fun doesn't stop there. Let's take this baby out for a spin: let's explore some implications of our definition. Figure 3 (a work commissioned in state-of-the-art Microsoft Paint) shows a system of just two packages. Package a has two classes - X1 and X2 - where X2 depends on three classes in package b.
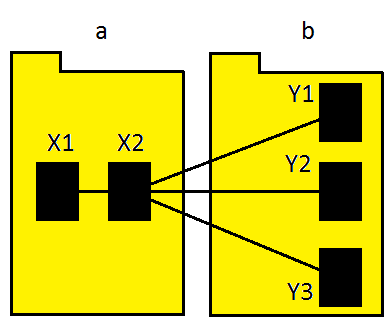
Figure 3: Strong package coupling of three dependencies.
So the package coupling of the system is 3. But could we refactor this system to reduce package coupling (without just lumping everything into one package)? Well, we could move class X2 into package b, as shown in figure 4.
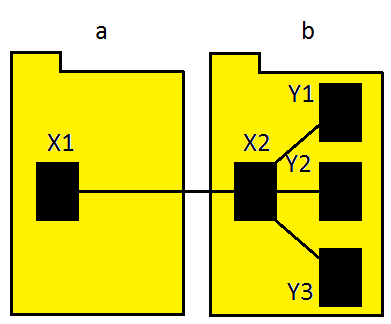
Figure 4: Refactoring to weaken package coupling?
By doing this, we have reduced the system's package coupling to just 1. Of course, other factors influence good design: we do not blithely shove classes around just to minimize coupling. Nevertheless, it's interesting to see what might result from such blind minimization.
And now, with our metric, we can write a simple algorithm to move a class sequentially into all packages of the system, record the move the yielded the lowest coupling, migrate the class permanently to that package and repeat the process for all other classes until no lower coupling can be found.
Doing so on Maven produces 100 coupling-reducing refactorings, each of which you can see applied in figure 5, in all its twitchy splendor (doesn't it look oddly ... organic? Like time-lapsed footage of neuron samples growing on that petri-dish gel that microbiologists are so fond of?).
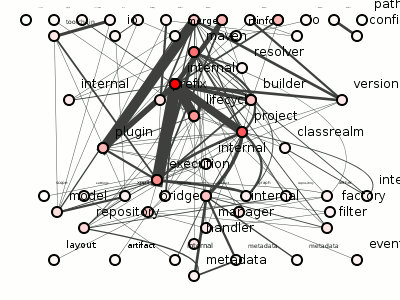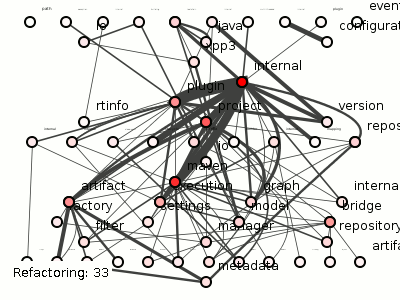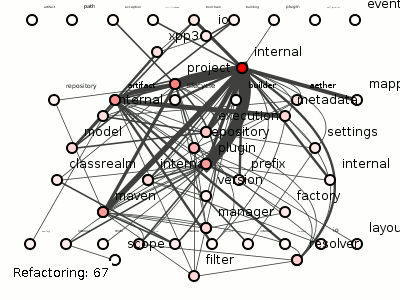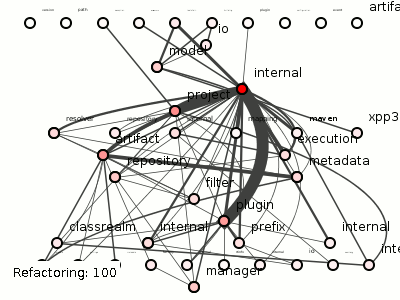
Figure 5: 100 refactorings to minimize Maven's package coupling.
(For fun, you can similar a similar treatment of the program FitNesse jiggling about in a whopping 12MB gif, with over 300 reducing refactorings, here.)
{kind=link}
Figure 6 shows the resulting, refactored Maven.
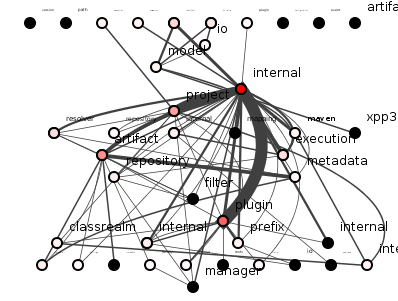
Figure 6: Maven with package coupling minimized.
Maven's final package coupling is 168, a 54% reduction. Is this an improvement? Perhaps, perhaps not. It certainly looks less tangled, but our naive algorithm seems to have evacuated entirely those packages along the top, and beneath the surface, that internal package has bloated to almost three-times its initial size. This was, however, a first attempt: we could easily tweak the algorithm to, for example, prevent increasing the size of the largest package, prevent moving classes on which multiple other classes depend, prevent emptying a package entirely, etc.
And note that this attempt has not collapsed the system into a single package: every connected package remaining in figure 6 has resisted the onslaughts of these barbarian refactorings. Why have these survived? Why have others been emptied of classes? Why have so many come to depend on internal? Even this first attempt has raised interesting design questions.
The point here is that by clearly defining what we mean by, "Package coupling," we have created a metric that allows objective system evaluation from that perspective, and that allows us to probe our own understanding of what package coupling means.
Finally, this was just one choice of design property: there are countless other properties we all think good design should have. Why don't we have well-established metrics for them all?
Summary 2.
There's nothing wrong with design principles that cannot be metricized (just look at popularity of the Single Responsibility Principle - could you write an algorithm to detect, "Responsibility," in source code?).
But that a design principle does not admit a metric is a concern. Code reviews can always descend into those ape-like screaming sessions when we have wishy-washy principles to club one another over the head with.
Metrics are not the solution: no metric will ever capture semantic constraints, for example. Metrics are, however, just one more way clarify what on earth we're all shouting about. And when has more clarity ever been a bad thing?
In your face, Goodhart!